
Hola estimados.
Me encuentro frente a un dilema, tengo un csv extenso con lineas separadas por coma, las cuales debo formatear a codigo insert, llenando un archivo .sql para ejecutarlo en oracle sqlplus, por lo tanto las estoy iterando una a una. Estoy usando este código regex [^,]+ para hacer un re.findall a mi variable que trae la fila para separar los datos.
Mi tabla OFAC_SDN tiene 12 campos:
campos 0,2,4, 5, 6, 7, 8, 9 y 10 enteros y campos 1,3 y 11 string (estos son los problematicos) ya que ay veces que el dato que estoy iterando trae comas internas en un dato string por lo que el resultado del findall no siempre tiene 12 resultados
Ejemplo de una linea del csv:
fila_archivo = "'19468,"GAZPROM DOBYCHA YAMBURG, OOO",0,"UKRAINE-EO13662",0,0,0,0,0,0,0,"Website yamburg-dobycha.gazprom.ru; Email Address PRIYEMNAYA@YGDU; Executive Order 13662 Directive Determination - Subject to Directive 4; Secondary sanctions risk: Ukraine-/Russia-Related Sanctions Regulations, 31 CFR 589.201 and/or 589.209; Registration ID 1028900624576; Tax ID No. 8904034777; Government Gazette Number 04803457; For more information on directives, please visit the following link: http://www.treasury.gov/resource-center/sanctions/Programs/Pages/ukraine.aspx#directives; Linked To: PUBLIC JOINT STOCK COMPANY GAZPROM.""
Se me ocurrió el siguiente código python para unir los campos string separados pero no me ha dado el resultado esperado:
def algo():
import re#funcion que obtiene el largo del iterador
def getIterLength(iterator):
temp = list(iterator)
result = len(temp)
iterator = iter(temp)
return result#funcion que determina si el dato inicia con comilla doble
def inicia(varchar):
res = »
if varchar[0:1] == ‘»‘: res = bool(True)
else: res = bool(False)
return res#funcion que determina si el dato termina con comilla doble
def termina(varchar):
res = »
if varchar[len(varchar)-1:len(varchar)] == ‘»‘: res = bool(True)
else: res = bool(False)
return res#tabla = GetVar(«tabla»)
tabla = «OFAC_SDN»
#id_tabla = GetVar(«id_tabla»)
id_tabla = «ID_SDN»
#fila_archivo = GetVar(«fila_archivo»)
fila_archivo = fila_archivo[1:len(fila_archivo)]
fila_archivo = «‘19468,»GAZPROM DOBYCHA YAMBURG, OOO»,0,»UKRAINE-EO13662″,0,0,0,0,0,0,0,»Website yamburg-dobycha.gazprom.ru; Email Address PRIYEMNAYA@YGDU; Executive Order 13662 Directive Determination – Subject to Directive 4; Secondary sanctions risk: Ukraine-/Russia-Related Sanctions Regulations, 31 CFR 589.201 and/or 589.209; Registration ID 1028900624576; Tax ID No. 8904034777; Government Gazette Number 04803457; For more information on directives, please visit the following link: http://www.treasury.gov/resource-center/sanctions/Programs/Pages/ukraine.aspx#directives; Linked To: PUBLIC JOINT STOCK COMPANY GAZPROM.»»
fila_archivo = fila_archivo.replace(fila_archivo[0:1],'»‘)
#SetVar(«fila_archivo»,fila_archivo)
res = re.findall(r»[^,]+», fila_archivo)
z = »
index = »
if getIterLength(res) > 12:
for idx, x in enumerate(res):if(inicia(x)==True and termina(x)==True): continue
if(inicia(x)==True and termina(x)==False):##Cuando termina en la siguiente iteracion
if(termina(res[idx+1])==True):
res[idx] = x+’,’+res[idx+1]
res.pop(idx+1)##Cuando no termina en la siguiente iteracion
if(termina(res[idx+1])==False):
index = idx
fin_index = getIterLength(res)-1
z = x
while(inicia(z)==True and termina(z)==False):
if(index<=fin_index): index =+ 1 z += ‘,’ + res[index] res[idx] = z del res[idx+1:index] z = » continue elemento = GetVar(«elemento») insert = » if ‘bad_add’ in elemento or ‘bad_cons_add’ in elemento: insert = ‘INSERT INTO OFAC_ADD (N_ENT_NUM,V_ADD_NUM,V_ADDRESS,V_CITY,V_COUNTRY,V_ADD_REMARKS,D_FECHA_PROCESO,ID_ADD) VALUES(‘ elif ‘bad_alt’ in elemento or ‘bad_cons_alt’ in elemento: insert = ‘INSERT INTO OFAC_ALT (N_ENT_NUM,V_ALT_NUM,V_ALT_TYPE,V_ALT_NAME,V_ALT_REMARKS,D_FECHA_PROCESO,ID_ALT) VALUES(‘ elif ‘bad_sdn’ in elemento or ‘bad_cons_prim’ in elemento: insert = ‘INSERT INTO OFAC_SDN (N_ENT_NUM,V_SDN_NAME,V_SDN_TYPE,V_PROGRAM,V_TITLE,V_CALL_SIGN,V_VESS_TYPE,V_TONNAGE,V_GRT,V_VESS_FLAG,V_VESS_OWNER,V_REMARKS,D_FECHA_PROCESO,ID_SDN) VALUES (‘ z = » for idx, x in enumerate(res): if idx == 0: insert = insert + x elif idx == 2 or (idx > 3 and idx < 11):
insert = insert + ‘,’ + x
elif idx == 1 or idx == 3:
insert = insert + «,'» + x + «‘»
elif idx == 11:
insert = insert + «,'» + x + «‘»
insert = insert +»,SYSDATE,(select case when max(«+id_tabla+»)+1 is null then 1 else max(«+id_tabla+»)+1 end from » + tabla + «));»
#SetVar(«insert»,insert)
algo()
En regex el resultado para esta linea son 15 matches.
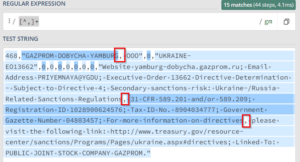
Necesito si alguien tuviera un mejor codigo regex o en su defecto un mejor codigo en python para poder unir estos campos y finalmente crear la sentencia insert.
Gracias!
Bueno, supongo que respondo tarde pero si alguien más tiene una duda parecida. En este caso, quizás no habría necesidad de hacer uso de un regex.
Básicamente teniendo la línea de ejemplo en un string podrías utilizar la función split. Por ejemplo: resultado = cadena.split(sep=»,») para indicarle que ira cortando cada que encuentre una coma.
En este caso, el resultado se guardaría en una lista. Ahora si las registros que desean guardar siguen siempre la misma estructura puedes utilizar las posiciones dentro de la lista para separarlos.
Ejemplo:
cadena = «hola soy, un ejemplo, de separar, por coma»
resutado= [‘hola soy’, ‘un ejemplo’, ‘de separar’, ‘por coma’]
Entonces, si la cadena sigue siempre la misma estructura y deseo extraer ejemplo y por coma simplemente sería.
texto1 = resultado[1]
texto2 = resultado[3]
y asi sucesivamente extraer por separado la posición dentro de la lista en la que se encuentre la información que quieren guardar.
Luego le pasan la variable al insert del módulo de rocket para base de datos que estén usando y listo.
Si por otra casualidad la estructura de la cadena cambia y lo que necesitan de la misma puede variar ahi si habría que utilizar la función regex y habría que ver particularmente como sería.
Espero que sea de ayuda para futuras dudas